Knot Embeddings in Improper Foldings
Published in the proceedings of the 7th International Meeting on Origami in Science, Mathematics, and Education.
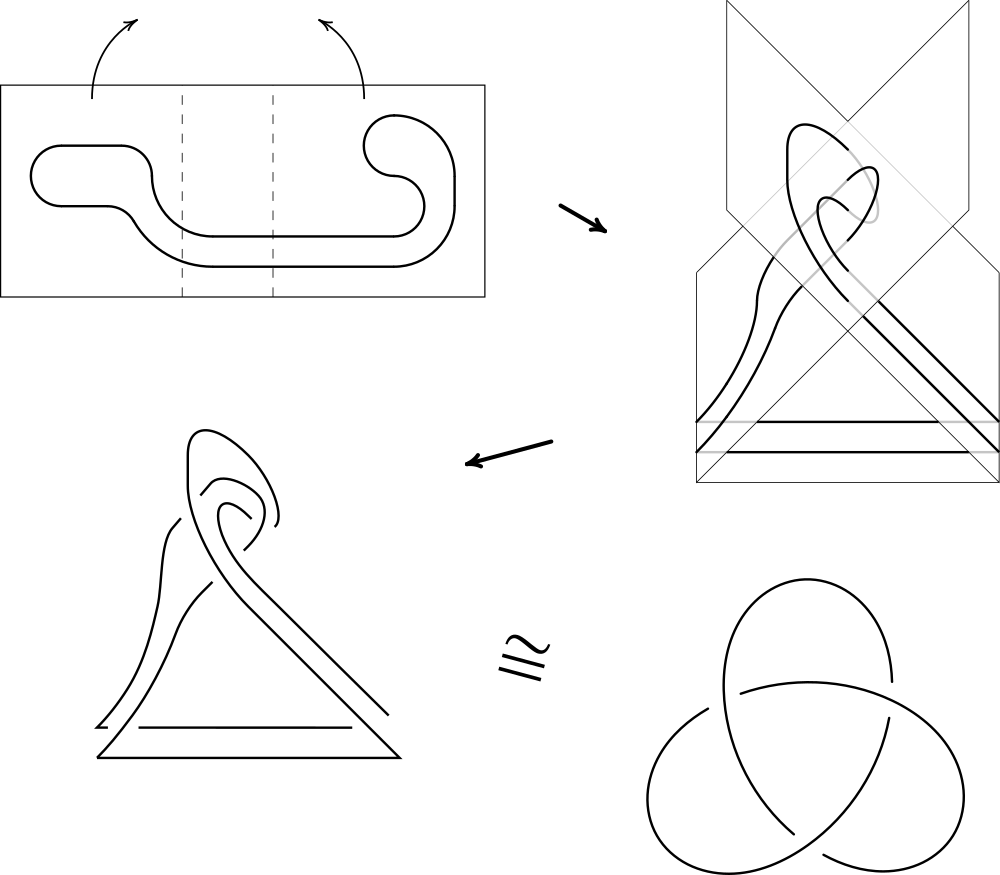
In this improper folding, a closed, simple curve is mapped to the trefoil knot.
This paper represents the first focused study of origami knot theory.
In it we introduce a topological model for origami folding, define a novel knot invariant—the fold number—based on origami principles, and resolve a 20-year-old conjecture of Jacques Justin.
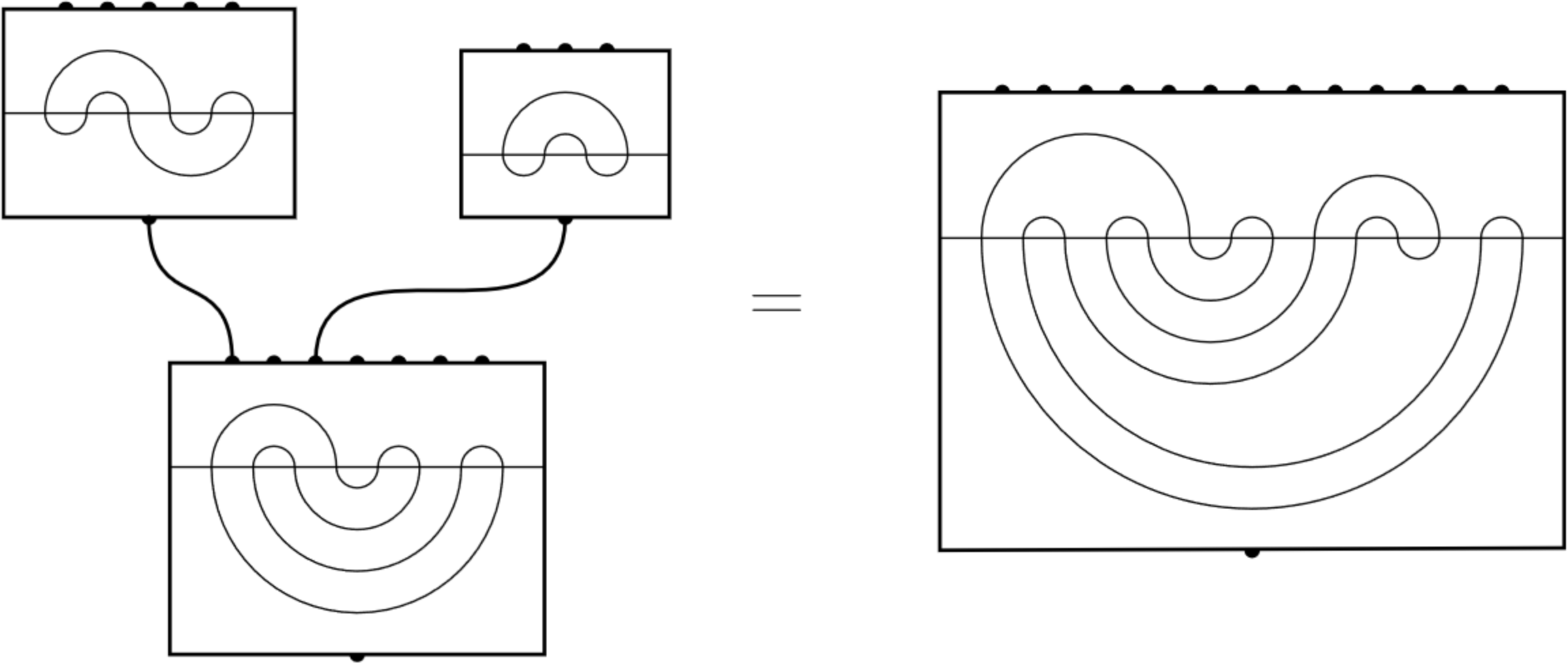
Origami can be formalized as the set of maps from the square to \(\mathbb{R}^3\) which are piecewise-linear (composed of creases) and which preserve the distance between points on the paper (no tearing or stretching).
Usually, the mathematical study of these origami maps is restricted to "physically-realizable" maps, which are the closure of the set of injective origami maps. (See Demaine & O'Rourke 2007 for an excellent overview).
However, if one allows an origami folding to nontrivially intersect (such as in the figure above), knots can be formed!
We show that knots are present as one-dimensional submaps of non-physically-realizable origami foldings, and indeed for any tame knot \(K\) there exists a folding which admits an equivalent knot as a submap.
This motivates the definition of the fold number of a knot \(K\) as the minimum number of folds in an origami folding which admits an equivalent knot to \(K\).
We present one loose upper-bound on this invariant, but many question about it remain, including whether or not it is constant.
Further, we address a conjecture made by Jacques Justin in his seminal 1997 work, "Towards a mathematical theory of Origami."
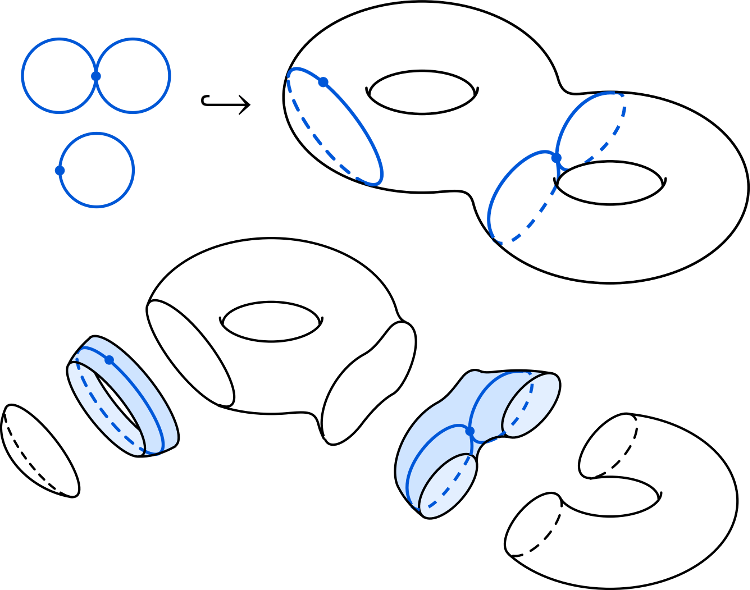
He proposed that if an origami folding is physically realizable, its perimeter is mapped to the unknot.
We resolve this conjecture positively in the case where the paper is simply-connected.